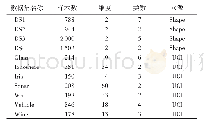
《表1 真实数据集信息:按风格划分数据的模糊聚类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
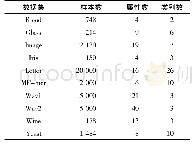
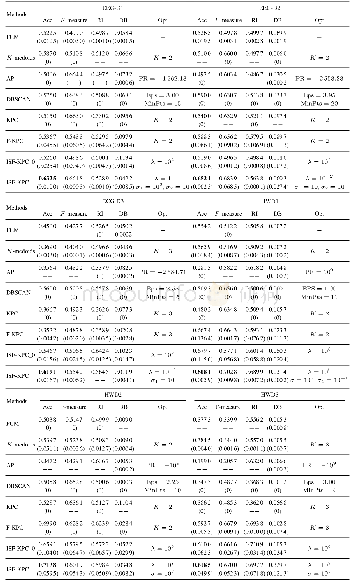
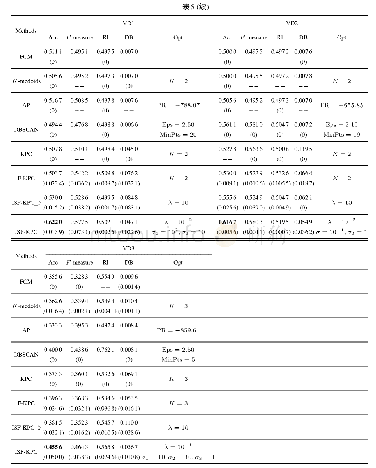
对于语音数据集,选取前5个样本提供者(speaker no.1~no.5)数据进行实验.对于手写英文字母数据集,选取3个书写者(姓名为:haoying、heliangliang、liuchuankai)数据中各连续500个样本进行实验,由于不同书写者的样本采集于不同时间段中,而数据采集的时间段为无关因素,故不选取数据的时间段(TIME)特征.对于EEG数据集,采用高斯核的核主函数分析(Kernel Principal Component Analysis,KPCA)[29]技术将样本维度降至70维进行实验.对于OSPI数据集,选取前3 000个样本进行实验,并对其符号属性进行数字化处理(将月份转换为相应数字,将true和false分别转换为1和0)[30].所有真实数据集信息如表1所示,更详细的数据集信息将在后续章节中具体介绍.
| 图表编号 | XD0038028300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.01 |
| 作者 | 沈浩、王士同 |
| 绘制单位 | 江南大学数字媒体学院、江南大学江苏省媒体设计与软件技术重点实验室、江南大学数字媒体学院、江南大学江苏省媒体设计与软件技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}