《表1 AEEEM数据集具体信息表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
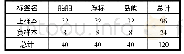
采用包含5组不平衡数据集的AEEEM数据库作为实验数据库,AEEEM数据库是由Marco D’Ambros等人收集的[15]。5组数据集分别是EQ,JDT,ML,LC,PDE。每个项目中含有61个度量:17个源代码度量、5个预先缺陷度量、5个熵变量度量、17个源代码熵度量和17个源代码流失度量。用于训练模型的样本数据的标签属性是布尔数据类型:buggy和clean。缺陷用“1”表示,没有缺陷用“0”表示。因此,预测结果的输出也是布尔型数据:1表示模块(一个函数或方法)有较高的缺陷倾向,0表示模块有较低的缺陷倾向。数据集具体信息如表1所示。
| 图表编号 | XD00195805100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.18 |
| 作者 | 刘影、孙凤丽、郭栋、张泽奇、杨隽 |
| 绘制单位 | 中国航天系统科学与工程研究院、中国航天系统科学与工程研究院、中国航天系统科学与工程研究院、中国航天系统科学与工程研究院、中国航天系统科学与工程研究院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}