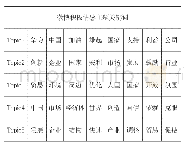
《表2:主题分类测试结果:基于文本挖掘的情报分析系统的研究与设计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
爬取下来的数据并不能够直接使用,需要对其进一步清洗。数据清洗将爬取得到的杂乱数据清理为简洁有效的干净数据,节约了存储空间、提升了后续处理的效率。本模块中主要解决了两个问题。其中一个问题是原始页面含有大量的噪声数据,例如Web标签、广告信息、页面弹窗和其他非新闻正文内容的其他数据等。因此,在对文本新闻内容进行数据处理之前,先过滤掉页面广告、弹出窗口等不相关信息,将Web页面转化成为不含噪音信息的统一的文本数据。另一个问题是页面编码不一致,如今全球使用计算机的范围十分广泛,计算机发展时间也十分久远,导致计算机存储数据采用的编码格式有许多种类,例如ASCII、UTF-8、GBK等等,在对文本进行去噪的同时,将所有文本的编码格式统一转换为UTF-8格式。
| 图表编号 | XD00193249300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.01 |
| 作者 | 邓雅倩、刘元高 |
| 绘制单位 | 第七〇一研究所、第七〇一研究所 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}