《表1 标注数据:融入表情特征的网络舆情情感分析方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
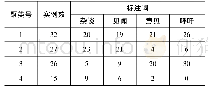
预处理分为3个步骤:首先,数据清洗环节包括删除非原创博文和博文噪声。博文噪声,是指网址链接、标签、特殊符号(“$”“#”“@”……)等;其次,使用Jieba分词脚本对博文进行分词;最后,去停用词。采用人工标注的方法,对微博数据进行标注。标注工作由课题组医学信息学专业的3名硕士研究生完成,3位成员共同标注8 000条语料,标注结果,见表1。
| 图表编号 | XD00193236600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.01 |
| 作者 | 靳春妍、牟冬梅、王萍、邵琦、杨鑫禹 |
| 绘制单位 | 吉林大学公共卫生学院、吉林大学第一医院、吉林大学公共卫生学院、吉林大学公共卫生学院、吉林大学公共卫生学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}