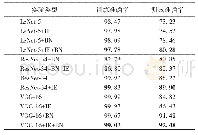
《表4 训练集机器学习准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
跨领域专利文本识别的最后一步就是使用机器学习方法结合已设置标签的训练样本找出最优的机器学习模型,并应用于全部专利数据集实现对相关专利的识别与分类。本文运用在文本多分类问题中常用的机器学习算法,如支持向量机(Support Vector Machine,SVM)、决策树(Decision Tree)、随机森林(Random forest)等,通过最结果的比较来选择最优的方法,得到较好的多分类效果。过程中运用多种方法对金融科技专利数据的特征进行学习,同时对专利文本向量构建算法,以及不同算法的参数等进行调整设置,达到的准确性如下表4和表5所示。选取标注样本的80%作为训练集,20%作为测试集。训练结果,如表4所示,各方法表现较好,SVM、随机森林方法准确率较高,准确率超过99%,而决策树准确率相对较差,平均准确率仅75%左右。
| 图表编号 | XD00193224000 严禁用于非法目的 |
|---|---|
| 绘制时间 | |
| 作者 | 高辰琛、刘琦岩、望俊成、张玄玄 |
| 绘制单位 | 中国科学技术信息研究所、中国科学技术信息研究所、中国科学技术信息研究所、中国科学技术信息研究所 |
| 更多格式 | 高清、无水印(增值服务) |




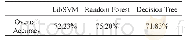
{kind=link}