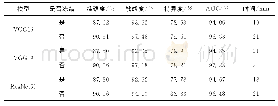
《表2 输入不同规模卷积层对结构计算性能效率影响》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《3D-ACC:基于3D集成电路的卷积神经网络加速结构研究》
由于加速器结构的固定不变性,卷积层输入维度的变化是影响结构实际性能效率的重要因素。实验时,假定计算结构的维度p为64,ACMB的深度d为128,每层slice的KERB为512 KB时,从表1中选取不同卷积神经网络模型的典型卷积层,统计输入维度变化对计算结构的性能效率的影响。为了减少启动、收尾时间对计算结构性能效率的影响,实验假设计算时的batch size为16,表2统计了输入不同维度的卷积层时计算结构的实际性能效率。从表2可以看出,卷积层输入维度变化对该计算结构的性能效率影响较大。C1的计算效率远低于C2,原因是C1的卷积核数仅为64,远小于pq=256,无法充分利用计算资源,导致计算资源浪费。C3的计算效率远低于C2,原因是C3的卷积核尺寸仅为1×1,无卷积窗口重叠的复用,在访存带宽受限时,C3的效率低于C2。C4的计算效率高于C3,原因是C4每个卷积核参数量更大,其计算密度更高。C5最低的原因是其卷积核个数仅为32,造成大量计算资源不能被充分利用。由上述分析可知,在访存带宽一定时,输入卷积层的卷积核数量以及尺寸较大时,可显著提升计算结构的计算效率。
| 图表编号 | XD00189238500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.05 |
| 作者 | 王吉军、郝子宇、李宏亮 |
| 绘制单位 | 江南计算技术研究所、江南计算技术研究所、江南计算技术研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}