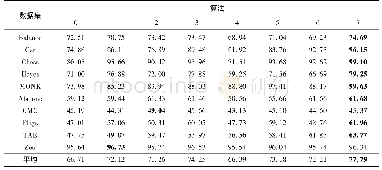
《表5 对比不同划分方法的正确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:加粗表示最好的结果.
为了验证属性加权、聚类以及特殊处理分类型属性的作用,实现了8个不同的结点划分方法产生决策树(见表5).算法0不进行聚类,直接使用各个类别的中心作为锚点,分类型属性使用众数代替数值属性的均值作为锚点向量的分量,计算样本到锚点距离时,各个属性上的距离使用式(4)计算得出并求和;算法1与算法0的不同之处是,使用Relief-F计算每个属性的权重,删除小于最大权重1/5的属性后,样本和锚点距离使用权重向量和式(4)计算得到的距离向量的点积;算法2与算法0的区别在于加入了聚类过程,k-modes算法用于分类数据集,k-prototypes算法用于混合型数据集;算法3结合了算法1和算法2;算法4~7分别对应算法0~3,分类型属性上关于簇心和样本到簇心距离计算采用2.2节描述的方法.算法7就是本文提出的算法.实验中生成的决策树均采用最小父母数为5的预剪枝策略,并对生成的决策树使用悲观剪枝算法进行剪枝操作.实验报告的正确率为10次10折交叉验证的平均值.
| 图表编号 | XD00186114500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.01 |
| 作者 | 刘振宇、宋晓莹 |
| 绘制单位 | 东北大学软件中心、大连东软信息学院网络安全与计算技术重点实验室、大连东软信息学院网络安全与计算技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |

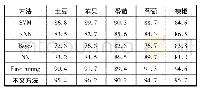

![表5 本文方法与传统方法的诊断准确率对比[24]](http://bookimg.mtoou.info/tubiao/gif/XAJT202008009_06300.gif)


{kind=link}