《表2 不同前置期条件下Logit模型与随机森林模型(ML)的表现对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《随机森林模型在宏观审慎监管中的应用——基于18个国家数据的实证研究》
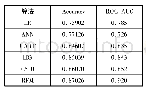
首先,在scikit-learn中对模型初始化,不对模型参数进行主观调试,对比此时的传统Logit模型和随机森林模型的表现。在Logit模型中,将数据进行Z-score标准化,设置迭代次数为10000;在随机森林模型中,由于树型模型对数据分布不敏感,因此,无需标准化,可直接对原数据建立500棵树且不对其剪枝。二者分别对超前1~4期建模,模型评价指标如表2所示。对比可知,无论是在训练集的准确率(Train Accuracy)方面,还是从测试集的四个评价指标来看,随机森林模型的学习能力和对风险的识别精度都显著高于传统的逻辑回归模型。整体而言,Logit模型仅在超前1年时对系统性风险有一定的捕捉能力,而在随机森林模型中,除lead-lag4年模型外,均对风险的分类和识别有一定参考意义,且模型表现更为稳定。
| 图表编号 | XD00185510200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.12 |
| 作者 | 王达、周映雪 |
| 绘制单位 | 吉林大学经济学院国际经济系 |
| 更多格式 | 高清、无水印(增值服务) |


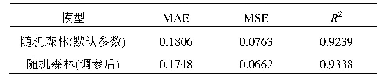


{kind=link}