《表7 使用不同数据集构建模型的评估结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
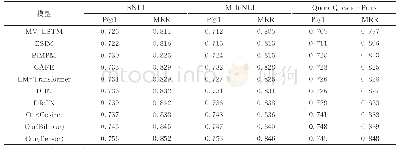
本文用来训练的数据集主要是电流数据、电压数据和功率因数数据.从数据的角度分析,可以了解使用哪个数据集进行模型构建更为准确高效.根据表3—5,计算每种数据集上4种算法实验结果的算术平均值,结果见表7.由表7可知,相对于电流数据和功率因数数据,使用电压数据的模型精准率虽然不高,但是其召回率和F1都最高,说明可以覆盖更多的窃电用户,因此可以认为电压数据用于反窃电模型构建最合适;使用功率因数数据进行建模分析效果最差,精准率只有56.75%,意味着实验中有近一半的疑似窃电用户识别错误,F1也只有66.28%.综合F1分析,可以认为在实际应用中,使用电压数据构建的反窃电模型最为高效可行.
| 图表编号 | XD00182336500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.15 |
| 作者 | 金保华、张明星、吴怀广、石永生 |
| 绘制单位 | 郑州轻工业大学计算机与通信工程学院、郑州轻工业大学计算机与通信工程学院、郑州轻工业大学计算机与通信工程学院、郑州轻工业大学计算机与通信工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}