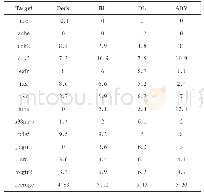
《表2 虚拟筛选富集因子(EF)结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
式中,TP代表预测正确的正样本数,TN代表预测正确的负样本数,FP代表预测错误的负样本数,FN代表预测错误的正样本数。模型的灵敏性分析SE(sensitivity)用于评估正样本的预测正确率,特效性分析SP(specificity)用于评估负样本的预测正确率。Nt为所有化合物分子个数,Ns是取样化合物数量,total actives为取样重活性化合物的个数,total molecules为测试集中所有活性化合物的个数,EFX%为打分结果前x%分子的个数(本文设定为2%),对于同一数据集式中total actives/total molecules的值是固定的。当EF>1时,说明该方法具有显著地活性化合物的富集能力,得到的结果是有效地,而且其富集能力随着EF的值得增加而增加。如表2所示,除了ace蛋白外,我们的DL筛选方法均能得到验证[6]。
| 图表编号 | XD00178859200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.05 |
| 作者 | 周世英、李福东、姜定 |
| 绘制单位 | 扬州大学信息工程学院、扬州大学信息工程学院、扬州大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}