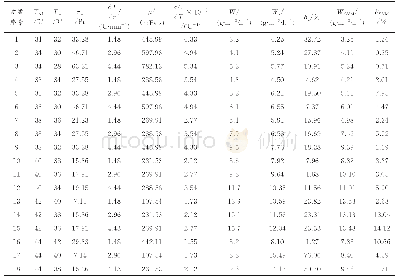
《表1 两种模型的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
Bi-RNN结构相对于DNN结构更加复杂,BiRNN对上下文相关性的拟合较强,理论上Bi-RNN相对于DNN更应该陷入过拟合的问题,而结果显示Bi-RNN的识别错误率更低,因此单纯用“过拟合”来解释是自相矛盾的。通过对DNN的神经元进行多次调整,当神经元数量到612时,其错误率最低为53.26%,相比Bi-RNN还是很高,因此并不能简单地通过“过拟合”来解释,说明产生这种现象根本原因在于Bi-RNN与DNN结构的差异性。受到协同发音的影响,语音中的各帧之间有着很强的相关性,每一个字的发音受到前后几个字的影响。在进行输入时,DNN是把相邻的几帧进行拼接,并且其输入窗口是固定的。而Bi-RNN在时序问题上能够更好地体现长时相关性,可以将过去与未来的信息同时输入得到输出结果,以作为预测当前的输入,能够更加深刻地了解其内在联系,因此降低了错误率。本文又与文献[17]所提出的改进CNN算法相比较,错误率也比其提出的方法较低,可见本文的Bi-RNN模型要比文献[17]所提出的改进CNN模型在语音识别方面性能要好。其实验结果如表1所示。
| 图表编号 | XD00178061700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 李鹏、杨元维、高贤君、杜李慧、周意、蒋梦月、张净波 |
| 绘制单位 | 长江大学地球科学学院、长江大学地球科学学院、长江大学地球科学学院、长江大学地球科学学院、长江大学地球科学学院、长江大学地球科学学院、长江大学地球科学学院 |
| 更多格式 | 高清、无水印(增值服务) |
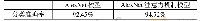




{kind=link}