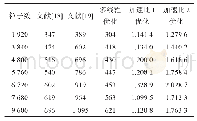
《表4 线程块内线程数对加解密速度的影响》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
CUDA程序中线程网格和线程块大小和维度的不同会极大影响算法执行速度。本文选择Windows 7/CUDA 8.1/CPU intel Xeon E3-1230 V2/GPU Nvidia Quadio600作为实验环境,固定线程网格和线程块的维度,只改变方案中的线程网格和线程块的大小(其内线程数目),对8 MB数据进行连续100次加解密操作,并进行3轮相同运算,记录每轮所耗时间。实验结果如表4所示。由表4可知,最长耗时是最短耗时的2.18倍,可见线程块大小的设置对SM4算法的运行速度具有很大影响。
| 图表编号 | XD00175831000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.10 |
| 作者 | 李秀滢、吉晨昊、段晓毅、周长春 |
| 绘制单位 | 北京电子科技学院电子与通信工程系、密码科学技术国家重点实验室、北京电子科技学院电子与通信工程系、密码科学技术国家重点实验室、北京电子科技学院电子与通信工程系、北京电子科技学院电子与通信工程系、密码科学技术国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}