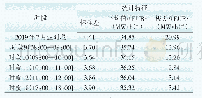
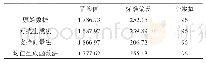
《表1 源数据与生成数据的统计特征对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
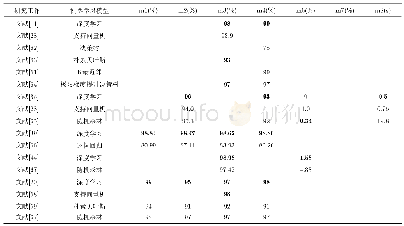
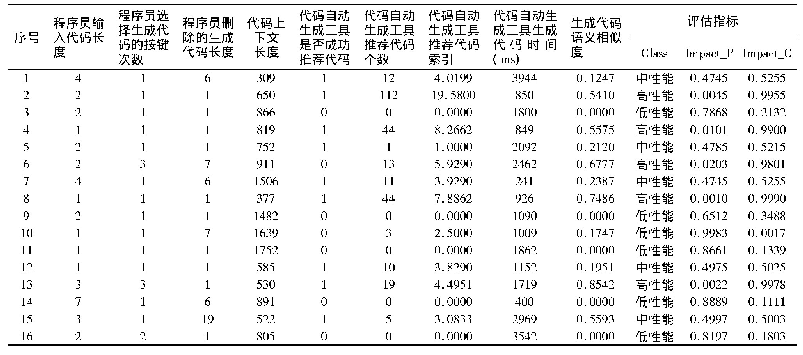
因此,以6个高斯数据集的混合作为GAN的原始训练数据输入,而GAN的结构如文献[13]设计为6个生成器和1个判别器。实验环境为Python3.7,硬件设施为Inter CORE i5 8th Gen,显卡为Intel(R)UHD Graphics 620和NVIDIA GeForce MX150。输入数据实例为8 000个,每一个训练批次包含64个实例,学习率为0.000 2,生成器和判别器都使用Adam优化算法。经过30 000次迭代后,训练结果如图7所示。图7中,底层紫色的数据点为源数据,而除紫色以外的颜色代表GAN的输出数据,6种颜色代表GAN拟合了6个不同的高斯数据集。在6个生成器的GAN结构中,生成器联合训练,且权重相同,因此每个生成器学习了一种数据模式。可以看出,包含6个生成器联合训练的GAN结构较好地模拟了源数据的分布,能够重现源数据的分布特征,而源数据与生成数据的统计特征对比如表1所示。
| 图表编号 | XD00175732300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 向南、张雄涛、豆亚杰、徐向前、杨克巍、谭跃进 |
| 绘制单位 | 国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}