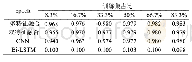
《表3 Yeast数据集分类预测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本节采用机器学习中的随机森林算法[17]预测蛋白质的定位信号。在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出类别的众数而定,由文献[18]在1996年提出。随机森林的优点在于可以处理高维数据,且对于不平衡数据集有较好的分类效果,因此对于Yeast数据集应使用随机森林算法进行分类,分类的分析结果如表3所示,图9为其接受者操作特性(receiver operating characteristic,ROC)曲线。在Yeast数据集的分类预测中,类别1的精确率和召回率都较高,而类别2相对较差,这是因为Yeast是个不平衡数据集,类别1和类别2的实例比大概为8∶1,总的精确率为0.94。而宏平均值(所有标签结果的平均值)为0.84,加权平均值(所有标签结果的加权平均值)为0.93的原因也是受到了类别1和类别2不平衡的问题的影响。由此可以证明,GAN同样复现了数据集不平衡情况,并不需要添加额外的训练信息。
| 图表编号 | XD00175732200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 向南、张雄涛、豆亚杰、徐向前、杨克巍、谭跃进 |
| 绘制单位 | 国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}