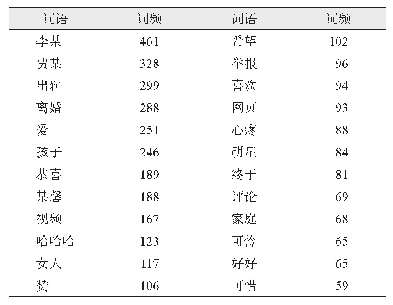
《表1 移民话题情感语料库构建》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《大数据驱动的社交网络舆情用户情感主题分类模型构建研究——以“移民”主题为例》
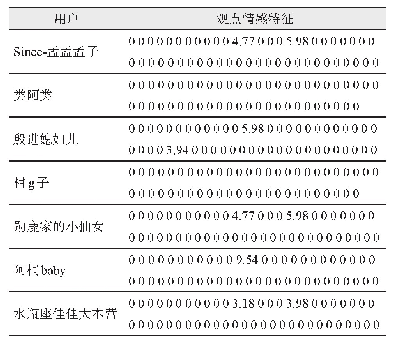
本文对文档进行分词,通过将文档中的文本归类为情感词和程度副词、否定词,以此判断情感词与程度副词或否定词结合产生的情感值[25]。如情感词与程度副词的乘积代表程度副词的程度值,情感词与程度副词的乘积乘以“-1”代表情感词前有否定词,最后,将一条语句的所有情感词的情感值得分加起来,大于0的归于正向,小于0的归于负向。本文选择BosonNLP情感词典构建社交媒体用户中文情感语料库。英文语料库的构建主要来自两个英文语料库词典,一个是MPQA词典(http://mpqa.cs.pitt.edu/),该词典的主观词语来自OpinionFinder系统,含有8221个主观词,并为每个词语标注了词性、词性还原以及情感极性;另一个是哈佛大学提出的General Inquirer情感词典(http://www.wjh.harvard.edu/~inquirer/homecat.htm),该词典收集了1914个褒义词和2293个贬义词,并为每个词语按照极性、强度等设置不同的标签。本文构建的“移民”话题情感语料库如表1所示。
| 图表编号 | XD00175577500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.26 |
| 作者 | 王晰巍、邢云菲、韦雅楠、王铎 |
| 绘制单位 | 吉林大学管理学院、吉林大学大数据管理研究中心、吉林大学管理学院、吉林大学管理学院、吉林大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}