《表1 子句长度随机实例上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
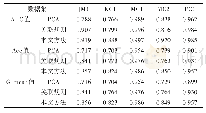
从编译效率上看:表1中,P-UKCHER未起到加速效果,反而极大地降低了编译效率,其原因正如之前分析,它们采用了PUAE算法直接合并多个EPCCL理论,算法1在第8行调用CDF子函数处理EPCCL理论所需时间要远远大于直接处理原始子句集所需的时间,而UKCHER算法串行操作中是直接对子句集进行处理的,因此P-UKCHER并未起到加速效果;当m<90时,imp P-UKCHER起到了一定的加速效果,然而加速效果并不明显,这是由于本文分配任务的策略采用的是按子句数划分,而对于随机子句长度的实例,这种划分策略负载均衡会很差;当m≥90时,imp P-UKCHER未起到加速效果,其原因在于UKCHER算法结合了动态在线推理方法,更适合子句数较多的实例.因此从编译效率的角度出发,UKCHER算法的并行编译算法同样更适合于子句数较小的实例.
| 图表编号 | XD0017139200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.03.01 |
| 作者 | 牛当当、刘磊、吕帅 |
| 绘制单位 | 吉林大学计算机科学与技术学院、吉林大学计算机科学与技术学院、吉林大学计算机科学与技术学院、符号计算与知识工程教育部重点实验室(吉林大学) |
| 更多格式 | 高清、无水印(增值服务) |


![表3 作业长度服从U[1,100]随机分布的实验结果](http://bookimg.mtoou.info/tubiao/gif/XBJX202007016_09400.gif)
![表2 作业长度服从U[1,20]随机分布的实验结果](http://bookimg.mtoou.info/tubiao/gif/XBJX202007016_09300.gif)
{kind=link}