《表1 实例〈20,m,10〉、〈25,m,10〉和〈30,m,10〉上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
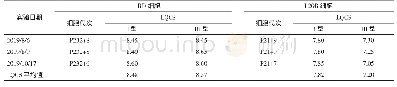
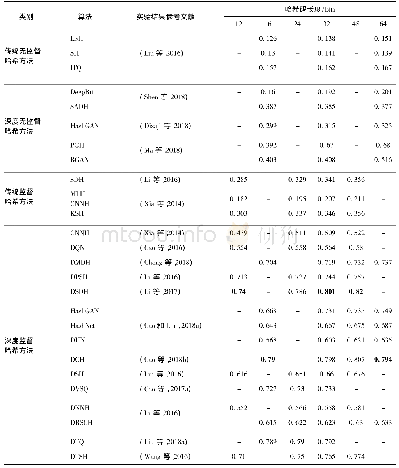
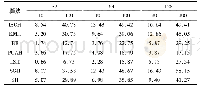
表2进一步验证了表1的结论。显然,impDKCHER算法在固定字句长度的实例上依旧能够显著提高DKCHER算法的编译质量,平均可提升18.6%。但相比于表1,表2中imp-DKCHER算法在较多的实例上未能提升DKCHER算法的编译效率,结合这些实例的实际情况会发现,当编译结果的规模较小时,imp-DKCHER算法的编译效率会低于DKCHER算法。主要原因在于:当编译结果规模较小时,意味着DKCHER算法中间结果EPCCL理论的规模较小,会导致使用RACE算法对DKCHER算法第2步求差操作的加速效果并不明显,甚至会低于规约中间结果EPCCL理论和最终结果EPCCL理论的总体运行消耗。
| 图表编号 | XD002463700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.05 |
| 作者 | 牛当当、吕帅、王金艳 |
| 绘制单位 | 西北农林科技大学信息工程学院、西北农林科技大学陕西省农业信息感知与智能服务重点实验室、吉林大学计算机科学与技术学院、吉林大学符号计算与知识工程教育部重点实验室、广西师范大学计算机科学与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
![表5 两组患者治疗前后血清IL-10水平比较[pg/m L,M(P25,P75)]](http://bookimg.mtoou.info/tubiao/gif/YYCY202033034_03600.gif)
![表2 不同浓度M+时,加合物[B+M]+的相对强度(M+=0、5×10-3mol/L、5×10-2mol/L,10~20e V)](http://bookimg.mtoou.info/tubiao/gif/HZDB202006008_14500.gif)
![表1 3组治疗前的指标比较[M(Q25,Q75),n=10]](http://bookimg.mtoou.info/tubiao/gif/SYLA202005009_02200.gif)
{kind=link}