《表4 不同算法下的G-mean值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
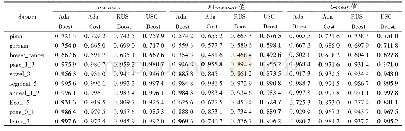
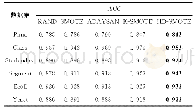
纵观表4和表5,可以发现K-SMOTE算法在这6个数据集上的G-mean和AUC值仅次于HD-SMOTE算法,但相较于RAND,SMOTE和ADASYAN算法均有较大幅度的提升,这说明K-SMOTE算法可以有效提升分类器的整体分类准确性。K-SMOTE算法利用K-means聚类算法对整个数据集进行不分标签地聚类,选择出满足失衡比率阈值(集群中多数类样本数量与少数类样本数量的比值)的集群,并且根据这些集群中少数类样本的密度这些集群进行过采样。因此该算法可以较好地解决不平衡数据集的类间和类内不平衡问题,这也是该算法取得较高G-mean和F-value值的主要原因。K-SMOTE算法所得到的集群中可能既包含少数类样本也包含多数类样本,有些集群可能因为不满足失衡比率阈值而被过滤掉。由于这些集群中少数类样本和多数类样本数量差距较大,分类器可能会对多数类样本产生偏倚,所以在这些被过滤掉的集群中需要加强分类器对其中少数类样本的学习。由于K-SMOTE算法过滤掉了不满足失衡比阈值的集群,因此无法加强分类器对这类集群中少数类样本的学习,从而降低了分类器对少数类样本的精确度。这也是该算法的G-mean和F-value值比DH-SMOTE算法低的主要原因,并且K-SMOTE算法对K-means聚类参数很敏感因此参数难以调优。HD-SMOTE算法恰好可以克服这些缺点,HD-SMOTE算法只对少数类样本进行聚类,这很好地克服K-SMOTE算法将少数类和多数类样本聚类为同一个集群的缺陷,并且算法对聚类参数并不敏感,不管在什么情况下HD-SMOTE算法都可以有效加强分类器对少数类样本的学习,增加了分类器对少数类样本和多数类样本的分类精度,因此HD-SMOTE相比较于K-SMOTE和其它算法更为合理。
| 图表编号 | XD00170280900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.16 |
| 作者 | 董宏成、赵学华、赵成、刘颖、解如风 |
| 绘制单位 | 重庆邮电大学通信与信息工程学院、重庆信科设计有限公司、重庆邮电大学通信与信息工程学院、重庆邮电大学通信与信息工程学院、重庆市质量和标准化研究院、重庆市质量和标准化研究院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}