《表1 几种方法目标检测性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《利用结构化SVM结合CNN的层次化目标检测与人体姿态估计方法》
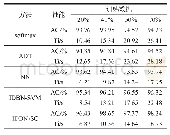
基于PARSE数据集,训练和测试了提出的方法。根据式(12)的损失增强推理损失Li。将本文的结果与文献[6~8]结果进行了比较,如图4所示。正确检测标准为PCP(percentage of correct parts)[8],如果检测到的肢体端点和地面肢体端点之间的距离在肢体长度的一半之内,则认为肢体被正确检测到。本文方法在头部、躯干、左臂、右臂、左腿以及右腿共六个部位的姿态估计性能均高于其他几种对比方法。此外,将本文方法与文献[6~8]方法对PARSE数据集中的图像im0001~im0008图像(图5)进行目标检测,结果如表1所示,类似于图5结果,本文方法对八幅图像的识别成功率也均高于对比方法。im0001~im0008是PARSE数据集中的前八个图像。识别成功率是平均PCP,这个数据是可以量化的。其中,文献[6]提出的带有附加潜变量的图形结构树模型以及文献[7]提出的多模态可分解模型,由于缺乏较好的先验模型,导致了其识别性能受到了较大限制。而文献[8]方法不能学习由深度学习特征而提取的参数。而且由可学习的特征所提取的参数不能基于latent SVM的误差来更新。本文提出基于结构化SVM卷积神经网络的层次化模型将SSVM模型转换为神经网络模型,因此它具有神经网络的固有能力,将误差反向传播到较低层,并计算确切的SSVM损失,同时通过基于次梯度的方法来学习原始SSVM解决了这个问题。因而,对比结果均显示其具有更强的识别性能。
| 图表编号 | XD00163340200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 孙新领、张皓、赵丽 |
| 绘制单位 | 河南工学院计算机科学与技术系、河南工学院计算机科学与技术系、山西大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}