《表1 关联词性序列样例:基于计量风格学的多层次特征在作者识别应用研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
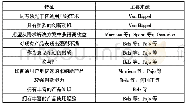
词性序列挖掘的第一步,找到所有的频繁项集,首先和一项序列结合生成k+1项,再通过最小支持度和频繁项集的子集也是频繁项集这一原理进行剪枝,其过程如图3所示。第二步是在所有频繁项集的基础上,计算项集的置信度,与最小置信度为筛选条件,得到满足最强规则(最小支持度和最小置信度)的序列项集,其样例如表1所示。
| 图表编号 | XD00163292700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.20 |
| 作者 | 钟敏、汪洋 |
| 绘制单位 | 武汉邮电科学研究院、南京烽火软件科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}