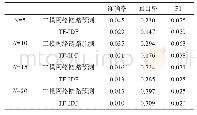
《表4 作者识别结果:基于计量风格学的多层次特征在作者识别应用研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
用于分类的机器学习方法有很多,常用的有逻辑回归,随机森林,K近邻算法等等。随机森林是集成学习器,具有较好的分类能力和稳定性[14]。逻辑回归分类器是简单易懂的分类器,其缺点是其适用场景和数据有限,不如随机森林强[15]。K近邻是理论比较成熟的方法,不需要训练模型,只在测试数据中进行计算,其缺点是在在数据量小的时候容易误分,只适合样本容量比较大的数据[16]。本文使用以上三种分类器,采用F1值作为评价指标,计算十次实验结果取平均值和方差,分别用来衡量分类器的并计算十次结果的方差(分类结果后括号内)的方差作为得到三个分类器表现如下表4所示。
| 图表编号 | XD00163292600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.20 |
| 作者 | 钟敏、汪洋 |
| 绘制单位 | 武汉邮电科学研究院、南京烽火软件科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}