《表2 实验参数设置:基于联合模型的多标签文本分类研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
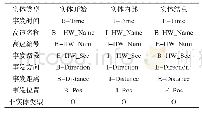
本文实验基于Keras框架,TensorFlow后端实现,编程语言为python3.6。通过多次实验及验证实验结果,选定最优的实验参数。由于提取的文本特征维度过大容易产生梯度爆炸问题,维度过少无法提取充分的特征信息,因此提取全局特征和局部特征的维度为设置为240。本文使用GloVe预训练的300维词向量,选定Adam(Adaptive Moment Estimation)作为优化器函数来优化神经网络,dropout值设置为0.5来防止过拟合。模型的具体参数设置如表2。
| 图表编号 | XD00163032800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.15 |
| 作者 | 刘心惠、陈文实、周爱、陈飞、屈雯、鲁明羽 |
| 绘制单位 | 大连海事大学信息科学技术学院、大连海事大学信息科学技术学院、大连海事大学信息科学技术学院、大连海事大学信息科学技术学院、大连海事大学信息科学技术学院、大连海事大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}