《表1 数据存储格式:多标签文本分类模型对比研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
经过以上步骤清洗,数据量最终为64万个,其中训练集60万个,校验集2万个,测试集2万个。文本的长度不同,对所有数据长度进行累和取均值,而后对数据进行截长补短。对数据的标签进行频率统计,保留前2 000个标签。数据的存储格式如表1所示。
| 图表编号 | XD00144924000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 姜炎宏、迟呈英、战学刚 |
| 绘制单位 | 辽宁科技大学计算机与软件工程学院、辽宁科技大学计算机与软件工程学院、辽宁科技大学计算机与软件工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
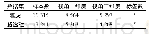


{kind=link}