《表3 在仿真数据集上Calinski-Harabasz(CH)指标统计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
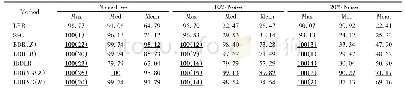
对于各算法的运行时间,由于PIFKM+-算法是在K-means聚类的基础上进行进一步的优化处理,所以在全部的数据集上,PIFKM+-算法比K-means算法的运行时间慢一些,但是在某些数据集上的运行时间要比K-means++算法快。为了进一步对3种算法进行评估,可以从簇内的稠密程度和簇间的离散程度来评估聚类的效果。在实验过程中采用了Calinski-Harabasz(CH)[19]指标,该指标值越大说明聚类效果越好,如表3所示。
| 图表编号 | XD00163025300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 李峰、李明祥、张宇敬 |
| 绘制单位 | 河北金融学院信息管理与工程系、河北省高校智慧金融应用技术研发中心、河北金融学院信息管理与工程系、河北金融学院信息管理与工程系 |
| 更多格式 | 高清、无水印(增值服务) |



![表3 本文方法与文献[1,14,15]方法在筛选数据集上的评价指标对比](http://bookimg.mtoou.info/tubiao/gif/JSJY202008034_08200.gif)

{kind=link}