《表3 T1组模式串行和GPU并行子试验模块计算耗时和加速比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
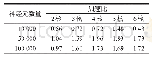
相比于单计算节点OpenMP并行,单GPU并行表现出了更加出色的加速性能,线性和非线性加速比分别达到67倍和72倍。具体分析串行和GPU并行条件下动量方程、质量连续方程和变量更新函数的加速情况,见表3。不难发现,动量方程因为计算量大,成为了加速效果最显著的模块,线性和非线性加速比分别达到141倍和103倍。另外两个函数模块加速效果基本相当,但远不及动量方程模块,抵消了部分加速增益。
| 图表编号 | XD00161435900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.15 |
| 作者 | 王宗辰、原野、李宏伟 |
| 绘制单位 | 国家海洋环境预报中心自然资源部海啸预警中心、国家海洋环境预报中心自然资源部海啸预警中心、国家海洋环境预报中心自然资源部海啸预警中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}