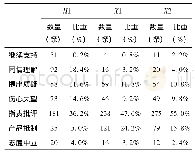
《表3 微博评论的编码统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《“引咎自责”还是“文过饰非”——修辞视角下企业形象修复策略研究》
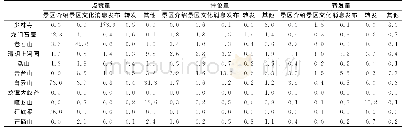
一方面,由笔者利用Nvivo 8.0根据网民在微博评论中体现的情感,对1500条评论进行背对背双盲编码。按照最大可能性原则,综合两人形成的编码,共形成14种情感类型编码,其中两人提出的相同编码个数12个,内部一致性为85%。根据Miles与Huberman的观点,代码的内部一致性在80%以上,属于可接受范围,本文编码已达到良好要求[32]。其后,在三条微博下进一步分别收集了200条,共600条评论进行饱和度检验,发现并未出现新的编码,说明理论已经达到饱和。将12个编码进行提炼整合,最终形成7种情感类型编码:继续支持、同情理解、提出质疑、伤心失望、指责批评(包括咒骂、嘲讽等负面语句)、抵制产品、态度中立。具体的数据如表3所示。从表中可以看到,三篇文本相比之下,H公司的形象修复效果最为显著,“产品抵制”与“指责批评”两种显著负面情绪比例较小,而且还有接近30%的评论表示谅解与支持。但由于H公司的服务品牌形象已经形成一定知名度,此次危机事件与所宣传的企业形象形成巨大落差,造成一部分消费者,尤其是忠诚度较高的顾客感到失望。相较之下,X公司的两篇文本取得正面效果较为有限,尤其是第一个声明发布之后,评论当中显著的负面评价占据高达70%的比重,而且评论当中的显著特点在于大量网民通过叙述自己的类似经历对企业进行控诉;此外,由于X公司表示不存在相关问题,也引来了大量网民的质疑,仅有极少数评论表示理解与原谅。在X公司发布第二个声明向公众道歉之后,评论当中的负面情绪仅出现较小的下降,正面的支持略有提升,但是大部分声音仍然是对X公司的指责与批评,而且很多评论对X公司的道歉与承诺提出质疑。
| 图表编号 | XD00161319400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 蔡礼彬、罗威 |
| 绘制单位 | 中国海洋大学管理学院、中国海洋大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}