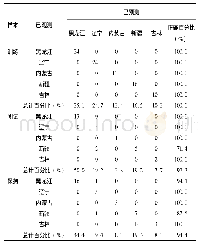
《表4 利用多层感知器进行大豆产地分类的训练子集、测试子集、保持子集结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于矿物元素指纹分析技术的中国北方大豆产地溯源研究》
从PCA结果来看,在地理区域较大的省份中,由于各种土壤、气候和生产要素而导致的元素含量变化范围大,可能导致无法区分来源。在这种情况下,本研究决定使用ANN来进一步挖掘和分析数据。MLP作为一类最常用的ANN,其结构赋予了它如大脑般相同的联想能力和容错性。此外,它具有自我学习和自适应能力,可以很好地解决多分类问题。将数据按照3∶1∶1随机分配给训练子集(60%)、测试子集(20%)和保持子集(20%)。其中,训练子集用于训练神经网络和构建该模型;测试子集用于跟踪训练中的错误,以防止训练过度;保持子集不参与模型的构建,而是用于评估最终的神经网络和评估模型“真实”的预测能力。表4显示,训练子集中的所有97个样本正确分类为各自产地内,正确率为100%。在测试子集的26个样本中,2个新疆样本被错误分类为辽宁样品,因此,在测试子集中,新疆的正确预测率为71.4%,而总的正确预测率为92.3%。在保持子集的36个样品中,1个黑龙江样品以及1个新疆样品错误分类为辽宁样品,黑龙江的正确预测率为94.1%,新疆的正确预测率为87.5%,保持子集总的正确预测率为94.4%。结果表明,利用MLP对4个产地大豆进行产地分类是可行的。
| 图表编号 | XD00159829200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.28 |
| 作者 | 赖翰卿、习佳林、何伟忠、王朝辉、毛雪飞 |
| 绘制单位 | 中国农业科学院农业质量标准与检测技术研究所、农业农村部农产品质量安全重点实验室、吉林农业大学食品科学与工程学院、北京市农业环境监测站、新疆农业科学院农业质量标准与检测技术研究所、吉林农业大学食品科学与工程学院、中国农业科学院农业质量标准与检测技术研究所、农业农村部农产品质量安全重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}