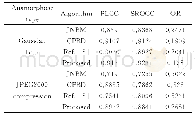
《表3 算法对比结果:基于共现概率训练的情感词典的扩充》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验表明本文算法明显优于传统算法。通过准确率、召回率、F值对本文提出的基于共现概率训练的情感词典扩充算法进行比较,有着明显的优势。本文改进了扩充情感词典的算法,准确率从0.75提高到0.86,显示出传统算法扩充构建起来虽然比较简单容易实现且分类速度快,但是分类准确度低不精确。召回率从0.66提高到0.88,F值从0.71提高到0.87,这表明本文算法模型具有较好的强健性。一般认为,正确率达80%以上的模型具有一定的生产价值,本文模型已经初步达到了这个标准,能适用于商业生产环境,为了下一步文本情感分类带来了高效性和准确性。
| 图表编号 | XD001579700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 季鹏飞、王先超、张顺香 |
| 绘制单位 | 安徽理工大学计算机科学与工程学院、阜阳师范大学计算机与信息工程学院、安徽理工大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}