《表4 对话块识别结果:面向任务型多轮对话的粗粒度意图识别方法》
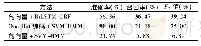 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在本节中,我们将通过实验选择出最佳的对话序列标注模型.我们选择了BiLSTM-CRF和隐马尔可夫支持向量机(Hidden Markov Support Vector Machines,SVM-HMM)两种模型进行对比.其中,SVM-HMM是Altun等人[29]提出的一种序列标注模型,其序列标注的表现优于隐马尔可夫模型、条件随机场等模型.因此,本文只选择了SVM-HMM进行对比.值得注意的是,我们采用了BIEO标签作为对话序列标注的标签集合,并对SVM-HMM采用了两种对话向量表示方法.其中,我们设定Sentence2Vec模型总迭代次数epoch为500,输出句向量维度d为100,BiLSTM-CRF模型总迭代次数epoch为150.最后,我们从3个角度分析了实验结果,结果如表2、表3和表4所示.
| 图表编号 | XD00157801100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 叶铱雷、曹斌、范菁、王俊、陈江斌 |
| 绘制单位 | 浙江工业大学计算机科学与技术学院、浙江工业大学计算机科学与技术学院、浙江工业大学计算机科学与技术学院、中国电信股份有限公司浙江分公司、中国电信股份有限公司浙江分公司 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}