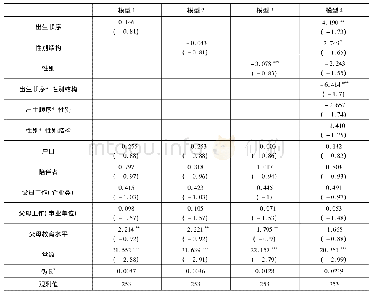
《表3 风险偏好的计量模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:括号中的数据为标准差,***p<0.01,**p<0.05,*p<0.1。
表(3)报告了非独生样本中被试风险偏好的Tobit回归结果,其中,被解释变量是被试的风险偏好,主要解释变量包括出生顺序、性别、子女结构。控制变量包括户口,陪伴者,父母工作和父母教育水平,其中父母的工作是作为多分类的虚拟变量纳入回归中的(农民务工类、企业类、事业单位类,并将农民务工类作为参照组)。模型(1)对出生顺序与风险偏好进行了回归,回归系数为0.146,说明二胎的风险水平高于一胎,但差异不显著,这与描述统计一致。模型(2)对性别结构和风险水平进行回归,性别结构的系数为-0.043,虽然不显著,但负的系数可以说明同性结构下被试的风险水平是高于混合结构的,这与本文的预测一致。根据描述统计分析可知,性别因素对风险水平影响显著,所以这里性别也作为一个主要变量纳入回归,如模型(3)显示,性别系数为-3.078,在1%的水平上显著,这与描述统计结果一致,男性的风险水平显著高于女性。模型(4)纳入全部主要解释变量与交互项,出生顺序与性别结构的系数分别为4.19和2.749,分别在5%和10%的水平上显著,加入控制变量和交互项后,出生顺序和性别结构对风险水平的影响由不显著变得显著,并且交互项系数也显著,说明交互项具有显著的调节作用。另外,父母的教育水平对被试的风险水平也有显著影响。
| 图表编号 | XD00152508300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.25 |
| 作者 | 汪良军、汤慧敏、虞艳云 |
| 绘制单位 | 浙江金融职业学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}