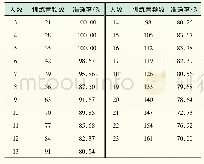
《表2 不同说话人模型下的识别率比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
同样选择50个说话人。在训练阶段采用不含噪音的语音数据训练说话人模型,在识别阶段,将噪音与干净语音的按一定比例融合,得到含噪的语音识别数据,对于含噪语音同样采用预处理,在卷积LSTM神经网络训练中,进行去噪音处理,然后利用得到的纯净语音,训练说话人模型GMM-SVM。同时实验对测试语音加完噪音后,提取MFCC及其一阶差分组成24位语音特征参数,分别训练GMM、SVM、GMM-SVM。从表2可以看出,当信噪比为30dB时,基本上识别不出说话人,但随着信噪比的增加,经过LSTM降噪处理,系统的识别率会比没有经过降噪处理的模型(GMM、SVM、GMM-SVM)的识别库率,验证了系统鲁棒性。
| 图表编号 | XD00148165200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 刘雪燕、李逵、袁宝玲 |
| 绘制单位 | 中山火炬职业技术学院信息工程系、中山火炬职业技术学院信息工程系、中山火炬职业技术学院信息工程系 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}