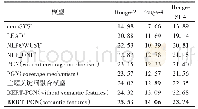
《表1 中文新闻文本数据集》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《RHS-CNN:一种基于正则化层次Softmax的CNN文本分类模型》
清华大学THUCTC文本分类工具提供的中文新闻语料(2),共有836 075个文本,如表1所示。该数据集将用于评估模型的分类效果(实验b和实验c),在每个分类中取70%作为训练集,30%为测试集。
| 图表编号 | XD00146259900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.15 |
| 作者 | 王勇、何养明、陈荟西、黎春 |
| 绘制单位 | 重庆理工大学计算机科学与工程学院、重庆理工大学计算机科学与工程学院、重庆理工大学计算机科学与工程学院、重庆理工大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}