《表1 不同方法运行10次的平均结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
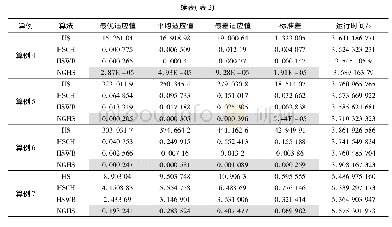
取12个拉丁超立方样本作为初始训练样本,且每种方法各运行10次以消除由不同初始训练样本及候补样本的随机性所产生的影响,其中GPC+MPP和GPC+MEMP以基于核密度估计的重要抽样(KDE-IS)生成的重要抽样样本作为候补样本.不同方法运行10次的平均结果如表1所示.此外,图1a,1b还分别显示了由不同方法得到的失效概率估计和最大相对稳定性ε随迭代次数Nit的变化趋势.显然,由表1和图1b可知,所提方法在满足失效概率分析精度要求的同时,还需要更少的功能函数评估次数.图2比较了不同方法在调用真实功能函数28次时DoE中训练样本的分布及预测的高斯过程分类边界.显然,所提自适应分析方法选择的训练样本分布更均匀且能更好地收敛到真实分类边界,即需要调用真实功能函数次数更少.
| 图表编号 | XD00145471500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.15 |
| 作者 | 张毅博、孙志礼、赵中强、赵经武 |
| 绘制单位 | 东北大学机械工程与自动化学院、东北大学机械工程与自动化学院、中车唐山机车车辆有限公司、中国人民解放军第93107部队 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}