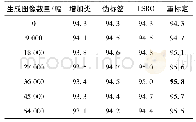
《表3 数量和不同标定方法对识别率的影响》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:加粗字体表示最优结果。
如表3所示,在生成网络为AT-PGGAN,分类网络为ResNet-50的基础下,分别对比不同数量的生成图像和不同标签的标定方法对识别准确率的影响。使用CompCars作为对比实验数据集,当使用“增加类”的方法时,由于其将所有生成类别标定为第K+1类,造成数据分布不均衡,从而使得识别准确率随着生成图像的增加而不断降低。而“伪标签”的方法在生成图像达到某一阈值前对准确率的影响不大,实验表明,在使用27 000幅生成图像时其准确率达到最高,较原始准确率增长了0.4%,而当生成图像数量继续增长时,准确率会持续下降。这是因为使用“伪标签”时,并没有考虑到生成图像的质量和标签是否正确对识别效果的影响,没有剔除一些生成质量差的图像,随着所生成的低质图像数量的增加,其识别准确率受到的影响越来越大。当使用LSRO方法对标签进行平滑后,准确率达到了95%,较“伪标签”方法有了一定的提高。使用“重标定”方法时,其获得的识别准确率均高于其他几种标签标定方法。当向分类网络中增加的生成图像数量达到36 000幅时,“重标定”方法显著提高了分类网络的识别性能,准确率达到了95.8%,较原始准确率有了1.5%的提升。而当继续增加生成图像的数量时,识别率有一些下降,这是因为当生成图像增加到一定程度时会对识别产生一些负面影响,属于正常现象。
| 图表编号 | XD00143040500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.16 |
| 作者 | 路强 |
| 绘制单位 | 合肥工业大学计算机与信息学院、工业安全与应急技术安徽省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}