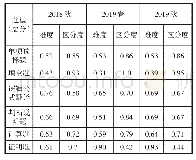
《表7 测验用字难度和区分度情况》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本研究利用TAM程序包的极大似然估计法(MML)估计测验用字的难度和区分度参数,测验用字的参数情况和分布情况见表7和图1。虚拟被试的识字能力在上述得到的模型基础上,以TAM程序包中的加权最大似然估计进行估计。虚拟被试的识字能力范围为-2.29~3.03,均值为0.01,标准差为1.03。由于虚拟被试的识字量是已知的,因此可以建立识字量和识字能力的对应关系,绘制出的散点图,如图2所示。
| 图表编号 | XD00142470300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.15 |
| 作者 | 温红博、李莹、杨子豪 |
| 绘制单位 | 北京师范大学中国基础教育质量监测协同创新中心、北京师范大学中国基础教育质量监测协同创新中心、北京师范大学教育学部课程与教学研究院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}