《表1 inception结构网络具体参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
人脸关键点检测和人脸表情识别两个任务密不可分,人脸关键点检测定位出人脸外轮廓和五官的位置,人脸表情的产生和变化也带动了人脸面部相关肌肉的运动,主要体现在五官周围,如:眉毛,眼角等。为了使得网络在优化过程中,最能体现表情类别的人脸区域(人脸五官周围),获得较高响应值,设计了一个多任务的网络在识别表情的同时增加了关键点定位任务。如图1所示,本文多任务网络是一个双流网络结构,图中的FC1为第1级网络中表情识别和关键点检测的全连接层,FC2为第2级网络中得出具体表情类别的全连接层。第1级网络用于检测人脸关键点,第2级网络用于识别人脸表情,两个任务共享了两个卷积层和两个池化层,使得模型能够更多关注人脸关键点附近的纹理信息。共享卷积层的卷积核分别为5×5和3×3,其中第1层卷积使用较大感受野可以融合更多区域的纹理信息。同时,考虑参数量增多容易导致过度拟合的问题,在除第1层卷积之外,其他卷积核均为3×3和1×1,池化层的核为3×3,步长为2。以每一个检测到的关键点作为高斯分布的均值,选取合适标准差执行高斯分布,增大关键点周围特征的权重。由于在以关键点为中心的邻域内,生成的置信图均有较大的值,允许预测的关键点存在较小的位置偏移。本文仅考虑关键点和表情之间的联系,用于训练和测试的3个数据集中均没有头部旋转角度较大的样本,因此关键点检测不会出现较大的偏移。基于上述原因,关键点检测网络设计较为简洁,只用了5个连续的卷积层,而表情识别的网络设计较为复杂,采用了一个类似于inception结构的网络(Szegedy等,2015),网络结构如表1所示,网络采用了4个分支,不同的卷积核融合不同尺度的特征,3个连续的卷积和池化操作对融合后的特征进一步提取高层次的特征并降维,最后两个全连接层融合全局特征用于表情分类。
| 图表编号 | XD00141911600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.16 |
| 作者 | 王善敏、帅惠、刘青山 |
| 绘制单位 | 南京信息工程大学自动化学院江苏省大数据分析技术重点实验室、南京信息工程大学自动化学院江苏省大数据分析技术重点实验室、南京信息工程大学自动化学院江苏省大数据分析技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |


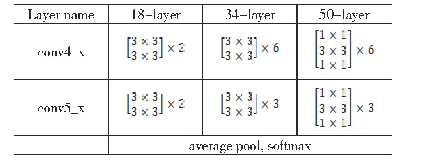


{kind=link}