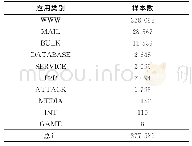
《表1 样本类别和数量统计信息》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验数据来源于清华大学的新闻数据集THUCNews,从中抽取了财经、游戏、房产、股票、家具、教育、科技、社会、时尚、时政等10个类别,每个类别13 000个文本,通过数据预处理对文本进行jieba分词,去除停用词,并且过滤文本长度超过2 000的新闻。详细的样本类别以及处理后的数据统计信息如表1所示。本文使用的嵌入向量是搜狗的中文新闻语料训练的嵌入向量。
| 图表编号 | XD00140226700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.31 |
| 作者 | 张波、黄晓芳 |
| 绘制单位 | 西南科技大学计算机科学与技术学院、西南科技大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}