《表1 训练数据:基于词向量的SVM集成学习社交网络抑郁倾向检测方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于词向量的SVM集成学习社交网络抑郁倾向检测方法》
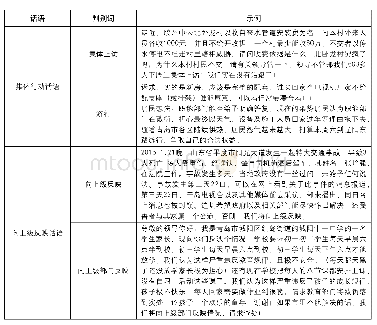
使用的数据来自新浪微博,选择352位有明显抑郁倾向的博主的微博作为正数据,共有35 962条微博文本,323位非抑郁症患者博主的7 297条微博文本作为负数据。筛选后得到28 654条微博文本的正数据,58 569条微博文本的负数据,如表1所示。经过3位心理学系的硕士研究生进行交叉检验,仅有10位用户存在争议,数据的可信度达到了97.5%。
| 图表编号 | XD00139390100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.10 |
| 作者 | 王垚、贾宝龙、杜依宁、张晗、陈响 |
| 绘制单位 | 北京世相科技文化有限公司、北京世相科技文化有限公司、北京世相科技文化有限公司、北京世相科技文化有限公司、北京世相科技文化有限公司 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}