《表6 与其他模型的对比(%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
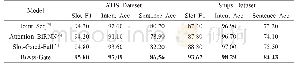
最后,也将DLS-CNN与其他当前表现较好的相似模型进行对比.特别是与Fiel等[8]提出的模型对比,因为DLS-CNN的处理过程与Fiel等提出的模型最为相似.由于Fiel等提出的方法对于上下行粘连的笔迹和位于上下行中间的笔迹不能正确分割,使得其在更具挑战性的ICDAR2013数据集上的鉴别表现不佳.实验结果显示,我们提出的模型在大部分的评估指标都取得明显更优的表现,并且在Hard top-2与Hard top-3上分别有29.8%与33.7%的提升,说明DLS-CNN弥补了基于行分割与CNN模型的不足.此外,DLS-CNN模型与Christlein等[24]提出的模型在同样使用取均值编码的情况下进行对比,DLS-CNN在Soft top-1与mAP两个评估指标上分别提升了8.2%与5.8%,表明基于统计的文档行分割与深度卷积神经网络的笔迹鉴别方法的模型能学得更具鲁棒性的特征,具有更强的泛化能力.但是我们提出的方法在Soft top-k的指标上并没有取得更加优异的表现.我们通过进一步实验找出那些未能正确查询的笔迹材料,发现我们的方法对粗笔所写的笔迹材料识别效果差.细笔/粗笔像素块的样例如图3(c)所示.可能原因有以下两个:1)由于数据集中粗笔写的笔迹材料极少,导致模型不能较好地学习粗笔所写笔迹材料的相应特征;2)由于粗笔所写笔迹材料不能较好地被正确分割,使得所获取的像素块不能保留更多完整的笔迹信息.具体实验对比如表6所示.
| 图表编号 | XD00135238400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 陈使明、王以松 |
| 绘制单位 | 贵州大学计算机科学与技术学院、贵州大学计算机科学与技术学院、贵州省智能医学影像分析与精准诊断重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}