《表4 不同K值时LADBMOTE的AUC值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
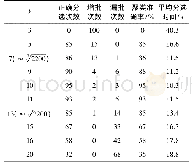
K值作为LADBMOTE算法中采样点的近邻个数,不仅决定了每个采样点需要计算的近邻数,还决定了集成学习中基分类器的个数。当K值太小时,有价值的近邻未被选择,因此可能会丢失高质量的合成样本,从而影响了集成分类器的效果。当K值比较大时,距离采样点较远,质量较低的样本或噪音样本被加入到近邻集合中,导致生成的样本质量较差。例如,当K=1时,算法只会选择距离采样点最近的样本,由此生成的样本会非常靠近采样点,这种合成样本的价值不高。而当K值非常大时,选择的近邻很可能位于另外一个类簇中,使得生成的样本落入了处于中间的多数类样本区域中,成为了噪音样本。因此,为了研究K值对算法的影响,本文设置K值的范围为[3,10],分类算法采用C4.5、NB、SMO、KNN和MLP,集成规则设置为Sum,AUC作为分类效果的评价指标。在20个数据集上的平均分类效果如表4所示。由表4实验结果可知,在以C4.5、NB、SMO和MLP作为分类器时,K设置为6时能够得到最优的AUC值。而以KNN作为分类器时,AUC随着K值增大而增大。当K≥8时AUC趋于稳定。在LADBMOTE算法中,K值应小于少数类样本的数量。然而,在非平衡率非常高的数据集中,少数类样本的数量非常少,较大的K值会导致算法无法运行。因此,综合分类效果与算法的可行性因素,K设置为6可以取得最优的分类效果。
| 图表编号 | XD00134718600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 杨浩、陈红梅 |
| 绘制单位 | 西南交通大学信息科学与技术学院、西南交通大学信息科学与技术学院、云计算与智能技术高校重点实验室(西南交通大学) |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}