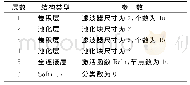
《表1 12个CNN模型的参数量及层数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文针对图像分类领域典型的12个深度学习模型进行研究分析(如表1所示).其中,Inception Google Net考虑3种结构模型,Inception V1基于Inception Module提高参数利用率.Inception V2进一步采用3×3的小卷积核替代5×5的卷积核,降低参数量,此外还通过Batch Normalization方法提升网络训练速度,提高收敛后的分类准确率.随后的Inception V4进一步结合ResNet以提升准确率.在残差结构中,本文考虑的ResNet-50,ResNet-101以及ResNet-152均为三层残差结构,其主要区别是conv3_x以及conv4_x下的残差结构个数不同,其中,ResNet-50在conv3_x和conv4_x下的残差结构个数分别为4和6,ResNet-101为4和23,ResNet-152为8和36,该网络结构通过不断加深层数以实现模型精度的提升.与此同时,本文考虑了轻量级模型MobileNet和ShuffleNet.MobileNet由Horward等人在2017年提出,它在计算量和模型尺寸方面具备明显优势,其架构由一个作用于输入图像的标准卷积层、一个深度可分离卷积堆栈以及最后的平均池和全连接层组成.MobileNet采用深度可分离的卷积来构建轻量级深层神经网络,可将标准卷积分解成一个深度卷积和一个点卷积(1×1卷积核).深度卷积将每个卷积核应用到每一个通道,而1×1卷积用来组合通道卷积的输出,这种分解可以有效减少计算量,降低模型大小.2018年Google公开的MobileNet_V2[29]通过引入残差结构和bottleneck层,使其更加高效.进一步,Ma等人[9]指出当前以FLOPs评估模型性能的不合理性,提出以网络实际内存消耗成本为度量标准,设计了更加高效的ShuffleNet_V2.
| 图表编号 | XD00134464300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 任杰、高岭、于佳龙、袁璐 |
| 绘制单位 | 陕西师范大学计算机科学学院、西北大学信息科学与技术学院、西安工程大学计算机科学学院、西北大学信息科学与技术学院、西北大学信息科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}