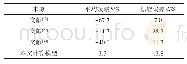
《表2 实验组2预测精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
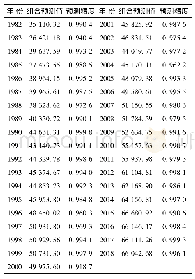
分析3组实验结果可知:ARMA模型总体上比AR模型的平均误差更小,预测精度更高。这是因为AR模型通过时间序列历史数据的线性组合加上白噪声建立自回归方程对当前数据进行预测,并且在预测的过程中认为历史数据中各个时期数值的随机波动可以相互抵消。但是在实际过程中,交换机在每个取样周期中新增加的流表项数量具有较大的随机性,各个时期所产生的随机干扰或误差并不能相互抵消,而这些随机波动的累积又会对预测结果产生较大影响。ARMA模型由自回归和移动平均两部分组成,综合了AR模型与MA模型的优势。自回归过程负责量化当前数据与历史数据之间的关系,移动平均过程负责解决随机变动项的求解问题。其中,移动平均部分对原序列有修匀和平滑的作用,可以有效的削弱原序列的随机波动。因此,ARMA模型对于交换机新增流表项数量的预测结果比AR模型具有更小的误差方差。与此同时,随着取样周期的缩短,新增流表项历史数据之间的变化趋势变得更加明显,ARMA模型的预测结果与实际结果之间的误差变小,预测精度也就更高。
| 图表编号 | XD00134389900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 刘钊、夏鸿斌 |
| 绘制单位 | 江南大学数字媒体学院、江南大学数字媒体学院、江南大学江苏省媒体设计与软件技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}