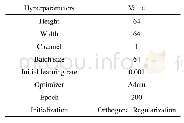
《表2 胶囊网络中的超参数设置》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
CGM M模型是在Keras平台上进行实验,在预训练词向量方面,使用从各网站爬取语料库中进行预训练得到的包含220万词汇的Glove词向量[3],以及维基百科中预训练得到的300维Fasttext词向量[4]通过提出的混合词向量方法得到高质量的600维词嵌入表示.采用Adam优化方法,学习率设置为0.01,辍学率设置为0.25,batch_size为100,以真实类别与预测类别的交叉熵作为损失函数,以最小化损失函数来训练整个模型,其余模型超参设置见表2.
| 图表编号 | XD00126567100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 王弘中、刘漳辉、郭昆 |
| 绘制单位 | 福州大学数学与计算机科学学院、福州大学数学与计算机科学学院、福建省网络计算与智能信息处理重点实验室、空间数据挖掘与信息共享教育部重点实验室、福州大学数学与计算机科学学院、福建省网络计算与智能信息处理重点实验室、空间数据挖掘与信息共享教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}