《表1 测试文本数据:基于word2vec和CNN的短文本聚类研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
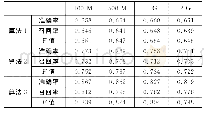
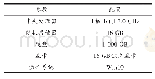
为了验证算法的有效性,本文从搜狗实验室(https://www.sogou.com/labs)下载的全网新闻数据(解压后大小为1.4 G)作为训练文本集训练词向量,训练过程设置词向量的维度为100。从互联网爬取的6个热点事件的微博,筛选出长度大于8个字符且少于140字符的文本数据一共1 020条作为测试文本数据。测试文本数据如表1所示。
| 图表编号 | XD00125764100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.25 |
| 作者 | 杨俊峰、尹光花 |
| 绘制单位 | 中原工学院计算机学院、中原工学院计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}