《表1 模拟样本生成及SVM分类实验》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
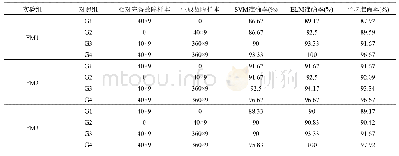
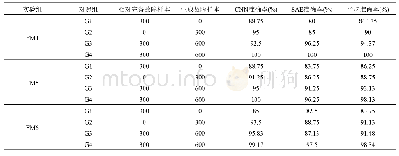
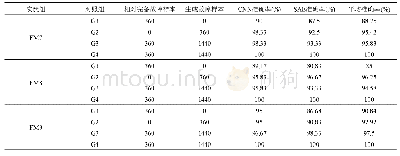
(1)实验一:模拟样本生成及SVM分类训练实验.按照笔者提出的模拟样本生成算法,以(样本非0特征权重之和<阀值)作为反例生成条件,不满足条件的模拟样本作为正例样本,随机模拟生成共1 000个正反例训练样本,测试样本全部为人工标注样本,观察不同阀值情况下,通过模拟样本训练得到的SVM分类器的分类效果.由表1可知,实验一的结果表明,随着非0特征权重之和这个阀值的增大,生成的反例样本数量增加、正例样本数量数据减少,通过模拟样本训练得到的SVM分类器的正确率也在随之发生变化,样本非0特征权重之和设为<1.0的阀值时,生成的模拟样本训练效果较好,随着阀值的增大,反例样本生成过多,训练得到的分类器的分类效果下降.
| 图表编号 | XD00123526400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 张洪胜、高海宾 |
| 绘制单位 | 淮南联合大学计算机科学与技术系、淮南联合大学计算机科学与技术系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}