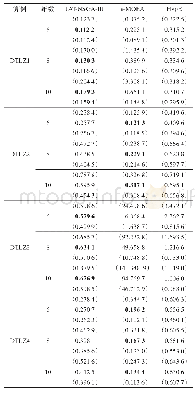
《表2 不同向量维度、激活函数的对比实验》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文通过对比同一个超参数在不同取值下的实验结果,为藏语语音识别模型提供最优的超参数.BLSTM-CTC模型训练过程中批次规模(batch size)大小为8,学习率为0.001.模型中隐藏层数为6层,迭代次数为1200次.向量维度的大小对藏语语音识别的声学模型有着不可忽略的影响.表2是其他参数规模不变的情况下,不同向量维度与不同激活函数下的模型对比实验.
| 图表编号 | XD00121915400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 南措吉、才让卓玛、都格草 |
| 绘制单位 | 泽库县人民医院、青海师范大学、青海省藏文信息处理与机器翻译重点实验室、青海师范大学、青海省藏文信息处理与机器翻译重点实验室、青海师范大学、青海省藏文信息处理与机器翻译重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



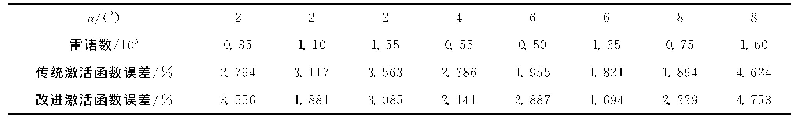

{kind=link}