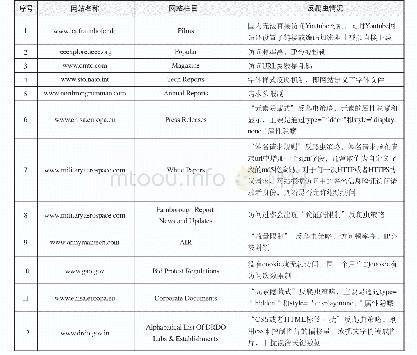
《表1 典型网站的代表性反爬虫措施栏目的应用策略》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在用爬虫工具爬取数据时,经常会遇到数据虽然在浏览器上显示但却抓取不到的情况,其原因也许是向服务器提交不恰当的表单被拒绝,也许是需要注册才能访问、IP地址已经被限制请求、复杂的验证码拦截等。我们共分析了50个国外科技门户网站,共133条信息源,其中网站栏目也叫“爬虫入口”(同一个网站包含多个信息源,但同一网站不同信息源的反爬虫策略可能不同,例如网站的文献类栏目跟视频类栏目反爬虫策略不同)。由于篇幅原因,表1列举了几个具有代表性反爬虫措施的典型网站栏目所应用的反爬虫策略。
| 图表编号 | XD00120214400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 张晔、孙光光、徐洪云、庞婷、曲潇洋 |
| 绘制单位 | 北方科技信息研究所、北方科技信息研究所、北方科技信息研究所、北方科技信息研究所、北方科技信息研究所 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}