《表2 研究主题聚类结果:守正拓新 开放融合——2019年图书情报与档案管理青年学者论坛会议综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《守正拓新 开放融合——2019年图书情报与档案管理青年学者论坛会议综述》
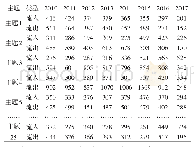
本文使用TF-IDF与Kmeans算法对投稿文章进行文本聚类,进而探索研究主题的分布情况。该分析过程利用Python编程按如下步骤实现:(1)文本预处理中,将每篇文章的标题、关键词以及摘要信息进行整合,使用jieba分词工具进行分词处理,并去掉停用词和标点符号,将关键词加入到分词词典中防止关键词被切分;(2)使用sklearn工具包将分词后的文本语料通过TF-IDF算法完成文本向量化处理,使用Kmeans算法构建聚类模型;(3)Kmeans算法首先需要确定聚类数量(k),在此使用计算簇内误差平方和(Sum of the Squared Errors,SSE)与elbow方法结合找出k值,对k依次取值2到20之间的数字,并依次计算不同k值对应的SSE,即样本距离最近的聚类中心的距离总和,结果显示聚类结果为16个类别时,SSE最小,且当增加聚类数量时无明显下降,因此选择16个聚类结果,并将离每个聚类中心点最近的5个词作为类的关键词;(4)进一步用训练好的聚类模型对原始文本进行分类,确定每篇文章所属主题,得出聚类结果(见表2)。
| 图表编号 | XD00115310700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.25 |
| 作者 | 樊振佳、翟羽佳、阎嘉琪 |
| 绘制单位 | 南开大学商学院、天津师范大学管理学院、天津师范大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}