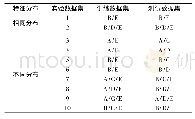
《表2 3组数据集上的文本分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验选用维吾尔文文本数据集Ucorp_A[14],Ucorp_A是平衡数据集(balanced dataset),包括政治、经济、体育、旅游、教育、文艺、法制、农业、医药保健和计算机等10个类别,每个类别有300篇文本,2/3用于训练,1/3用于测试。从Ucorp_A训练集中的每个类别中分别取出10、20和40个等不同数量的文本作为初始训练文本集(Labeled data)。再从每个类别剩下的文本中分别提取出100个文本(总共1000个文本)并去除类别标记作为未标注样本集(Unlabeled data)。最后从Ucorp_A测试集中的每个类别中分别取出60个文本(总共600个文本)作为测试文本集(Test data)。这样,总共产生3组数据集。第一组数据集中训练集的每一类只包含10个已标注文本。第二组数据集中训练集的每一类只包含20个已标注文本。第三组数据集中训练集的每一类包含40个已标注文本。这3组数据集中的文本分布情况见表2。
| 图表编号 | XD00111173700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.16 |
| 作者 | 阿力木江·艾沙、殷晓雨、库尔班·吾布力、李喆 |
| 绘制单位 | 新疆大学信息科学与工程学院、新疆大学网络与信息技术中心、新疆大学信息科学与工程学院、新疆大学信息科学与工程学院、新疆大学网络与信息技术中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}