《表2 随机森林最高准确率百分比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
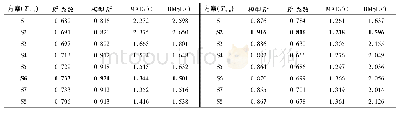
由表1可以看出,使用词袋、Word2Vec、GloVe对数据进行向量表示后用逻辑回归分类模型分类,3个数据集均为保留停用词准确率更高,其中使用TF-IDF对数据一和数据三进行分析也同样为保留停用词准确率更高,但对数据二分析则表现为去除停用词准确率更高,这是由于数据二的分类更多地依赖于与灾难相关的专有词汇,停用词和灾难相关性较小,影响TF-IDF中的词频及逆向词频的计算,所以去除停用效果更好。表2表明,使用随机森林分类模型和词袋或TF-IDF向量表示方法时,保留停用词准确率较高;相反的,使用Word2Vec和GloVe特征模型时,去除停用词效果较好,产生这种结果的原因之一是随机森林初始随机值不固定。表3为使用决策树分类算法,词袋、TF-IDF、Word2Vec这3种向量表示方法均为保留停用词准确率更高,而GloVe在对数据一和数据二进行分析时,去除停用词效果更好。表4分别为使用SVM和kNN分类算法,此时除了数据二,其它均为保留停用词准确率较高,产生这种现象的原因之一为数据二内容的特殊性。
| 图表编号 | XD00111168100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.16 |
| 作者 | 高巍、孙盼盼、李大舟 |
| 绘制单位 | 沈阳化工大学计算机科学与技术学院、沈阳化工大学计算机科学与技术学院、沈阳化工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}